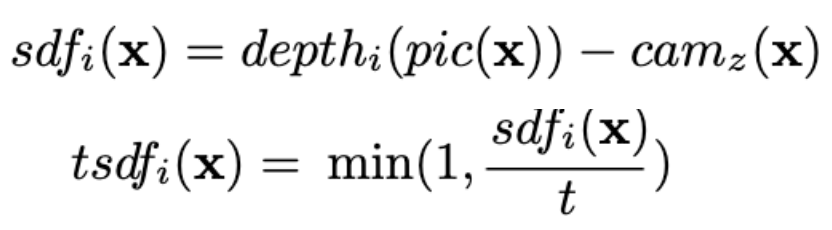
|
In this project, we were inspired by this paper to reconstruct a 3D mesh of an object from a video. This can be divided into three steps: creating depth maps from the frames of the video, fusing the depth maps into a voxel volume, and creating a mesh from the volumetric representation. In our process, we mainly focused on the second step, implementing Truncated Signed Distance Function (TSDF) in order to fuse depth maps together into a volumetric representation.
We used data from the 7-Scenes Dataset from Microsoft, which contained color images of scenes, associated depth maps, and the camera position matrix of each frame. We were then able to use these as inputs into our algorithm!
The general procedure of the algorithm is as follows:
The actual TSDF algorithm that we coded consisted of the following steps for each frame:
After we build the TSDF and color volume, we extract the mesh of the scene using the Marching Cubes Algorithm provided by the SciKit-Image API. The Marching Cubes Algorithm is used to extract a polygonal mesh of an isosurface from a three-dimensional discrete voxel.
The core ideas for the TSDF algorithm stem from the following two formulas. Credit goes to this paper for these equations, as well as for the insight for how to implement them.
|
|
Fundamentally, TSDF is just a representation of our surface, where we store a signed distance to the nearest surface for each voxel. The SDF itself is the distance between a voxel and the closest object surface, where a positive SDF corresponds to being in front of the object, while negative means its behind. The TSDF is the "truncated" version of the SDF, which we do using a chosen truncation constant t. The reasons that we truncate the SDF are that large distances are not relevant for surface reconstruction, and it helps to reduce our memory footprint. We used a truncation constant of voxel_size * 5, chosen after analysis from the papers we read. Additionally, we initialize the TSDF to have a minimum value of 1.
The other terms referenced in the equations are as follows:
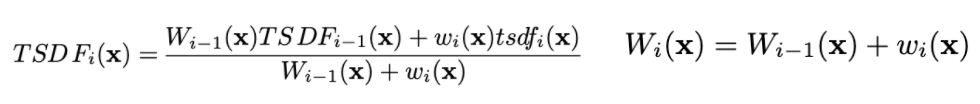
|
Essentially, we can just compute a weighted average of the previous TSDF with our current TSDF to compute an overall representation, and doing this across all frames in the scene will yield surprisingly accurate results! For our purposes, we initialized all weights to be one, causing each TSDF calculation to be weighted evenly, but depending on your implementation, you can also have heavier weights for closer or more direct angle measurements, with slightly more precise results.
Our first problem we encountered was when we weren’t too sure about what we should work on implementing in the whole algorithm, so we decided to try creating a point cloud from the frames of our video directly, which we could then use to create a mesh. While researching how to implement point cloud generation directly, we decided to use an application to visualize and generate the point cloud. Many of the applications we tried failed to compile due to various reasons, such as dependencies that our computers could not support. When an application was finally found however, there was no way to save the point cloud without paying a large sum of money. Here, after consulting with a TA on our process, we decided to change our approach to just implementing TSDF and depth fusion instead.
After deciding on implementing TSDF, we managed to get the depth map and color images for each frame of our video from a pre-trained neural network; however, we also needed to extract camera positions from our frames, which the neural network could not do. At this point, we first tried to extract data from the IMU of our smartphone, but this proved to be too difficult as no one in the group had worked with the IOS API. Another idea we looked into was finding an application that could extract the camera positions. Unfortunately, we could not find one successfully, and we had to go back to the drawing board. Our final idea was to try to create a perfect 360 degree video. This way we could apply a constant rotation matrix to each frame, without having to properly calculate a very accurate rotation matrix. In the end though, we ended up using the 7 Scenes Dataset as mentioned earlier, with given camera positions and intrinsic camera matrix, since we concluded calculating it ourselves was too challenging with our current resources.
Once we had a working algorithm, there were still many performance issues. It would take hours to finish rendering the volumetric representation, and our code needed to be more efficient. To do this, we condensed many of our computations into numpy matrix operations, taking advantage of numpy’s heavy optimization. By using numpy instead of for loops, our runtime decreased many folds, and what took several hours to render only took several minutes.
Below are the results of running our code on the depth maps from the dataset! Provided our some examples of the input images, their corresponding depth maps, and the final result:

|

|

|

|
We did most of the work together, but researched separately. For example, we each read separate research papers and came together to put our ideas together. We also constructed our project pipeline together.
For coding specifically, we live shared using Visual Studio Code, and coded on the same Python file at the same time. After we finalized our reconstruction pipeline, each of us took charge of different parts, such as implementing the integrate_tsdf_volume(...) and TSDF(...) functions, as well as creating the VolumetricTSDF class. We then came together to process the full implementation, and made sure everything worked and compiled smoothly as we debugged. We also worked on the presentation together, figuring out how to work the topics into the concise slide format, as well as distributed speaking roles evenly while presenting. Lastly, we all took a lot of time to write this final report!
Divide and conquer. :)
Our plan is to implement a method for the construction of a 3D representation (a mesh with a texture) of an object on a smartphone with a monocular camera. Basically, from a 360 degree video of a selected object, we hope to be able to parse the data in the video in order to accurately create a mesh that represents the geometry and texture of the chosen object.
In science, objects need to be tested and modified, but real life objects take resources and time to physically recreate. Because of this, we would like to test on reconstructed digital objects instead. Reconstructing an object into a 3D digital model can be useful for many applications, and with this 3D model, simulations can be performed on an object many times, without wasting too many resources. Another application aside from simulations where this technique can be useful is during mass production. With 3D printing, objects can be made cheap while still being functional.
We will create a video that showcases the abilities of our mesh reconstruction! The video will contain a 360 degree video of the chosen 3D object, and then show its corresponding 3D representation.
We will judge our performance on the accuracy of our 3D mesh reconstruction, gauging a range of acceptable error for the model compared to the physical object. Additionally, we aim for an acceptable runtime; the paper given explains that the optimal runtime is about one minute, so we aim for a runtime of less than 10 minutes.
We are planning to build a program that reconstructs a 3D object from a 360 degree video and an IMU provided by a smartphone. Our baseline for this project would be implementing 3D mesh reconstruction successfully, not necessarily based on a video.
We hope to build a program that can do 3D reconstruction in around 1 minute and yield a relatively accurate 3D model. We then hope to transfer this program onto a smart phone application for portable use.
What we have accomplished:
First, we have flushed out the pipeline of our 3D reconstruction. First, we would use High Quality Monocular Depth Estimation via Transfer Learning to get a series of depth map from a 360 degree video of a object. After we have depth map computed for each keyframe, we would then fuses all depth maps into a volumetric representation of the object, using truncated signed distance function (TSDF). Then we would try to reconstruct 3D meshes with the generated TSDF voxel volume. And finally, do texture mapping, map each keyframes of the video to the reconstructed mesh.
Preliminary Results:
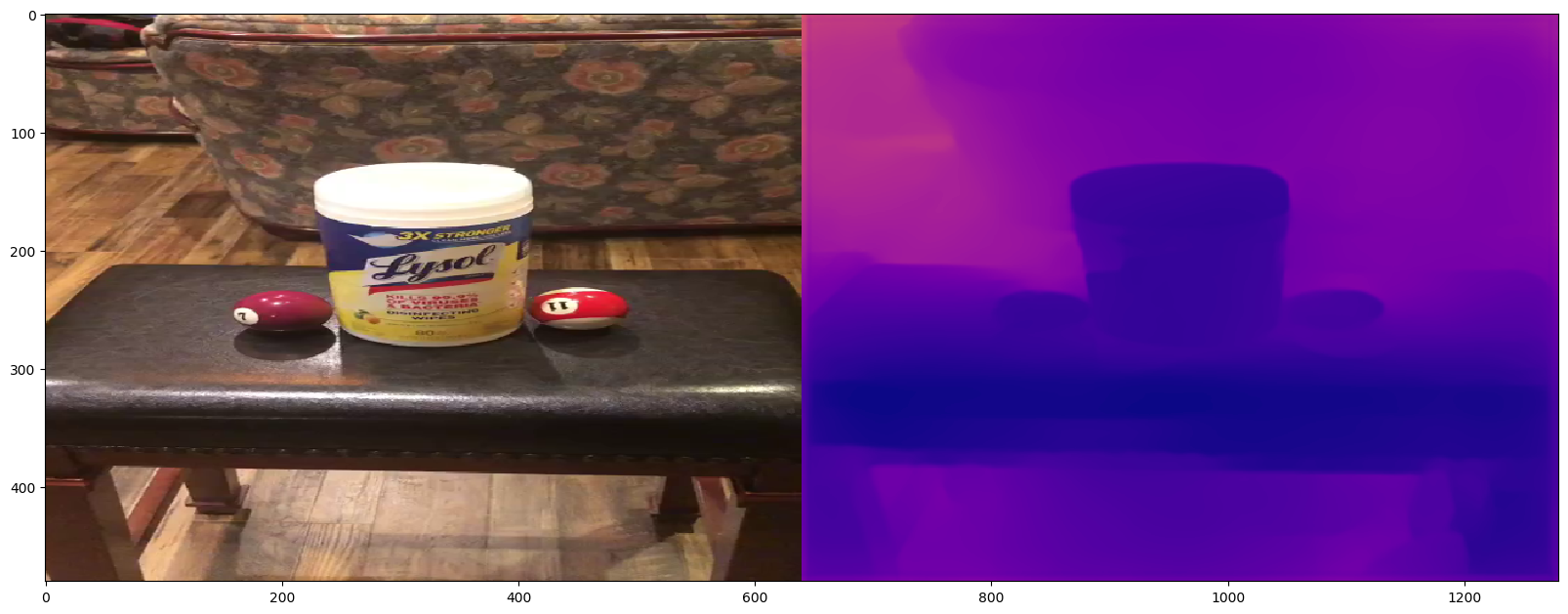
There are 3 results we accomplished for this checkpoint. First, we flushed out our 3D reconstruction pipeline (as shown above). Second, we learned how to use High Quality Monocular Depth Estimation via Transfer Learning API with pre-trained model to extract frames from a 360 degree video and generate depth map for each frame (results shown below). Thirdly, we have researched more knowledge and methods about how to code TSDF [Resource1: Fast and High Quality Fusion of Depth Maps. Resource 2: Dense Reconstruction On Mobile Devices]
Key Frames with Depth Map:
|

|

|

|
Reflection on our plan:
Some behind the scene story: Before we jumped into the research of this project, we just simply thought 3D reconstruction is a super cool idea. However, what we did not expect was that 3D reconstruction is actually a very complicated yet intriguing topic. Many researches have been done on this, and it is still one of the cutting-edge researches in computer vision. So this gave us a lot more thrill driving forward this project. "We are involved in the cutting edge technologies!"
Somethings we have learned through starting on a project: First, getting started on the project is very, very tough. In the first couples nights working on this project, we had completely no clue what we are doing. We are overwhelmed by the complicated terms and methodologies mentioned in the paper and started rashly searching for random APIs and try to put pieces back together. This had led us nowhere. The lesson is here is that even though sure, the key to start something you don't know how to is to gather as much information as possible, it is very important to first try to understand the fundamental structure of what we will be doing and the links between each major parts. Then research the parts we need based on the structure incrementally. For example, the good practice we finally did is to really break down the fundamental structures of each paper, identify major pieces, and research how to do each individual pieces more in depth later on. Because of this, we conquered our fear and came up with a pipeline for our 3D reconstruction as shown above.
Future plans:
The majority of the rest of our project would be coding the TSDF part to fuse the depth map into a volumetric representation of the object. After doing so, if we have time, we will code the module that performs mesh reconstruction from TSDF volume; otherwise, hopefully we can find an API that does it. Last but not least, we hope to integrate project 2 (The project we did for editing mesh) into our texture mapping process.